시험 공부 대비겸 토론에 올라온 주제를 바탕으로 공부를 해보았다!

In what sort of situations would SVM be better than KNN (and why), and in what sort of situations would KNN be better than SVM (and why)? Please think about this yourself, and discuss your own thoughts -- I don't just want someone to do a Google (or DuckDuckGo, etc.) search for an answer!
Some possible things to think about:- Think about how data points might be clustered.- What if one class of point is much more common than the other in the data you're using to build the model? [Preview: this data is called the "training data", as we'll see soon.]- What does it mean (for KNN and for SVM) if you see that the classification of your points is very mixed (lots of red scattered within blue, and lots of blue scattered within red)?- What do you think the SVM/KNN implications are if part of what you want to get out of a model is how likely it is that the classification of a new data point is correct?
SVM(Support Verctor Machine)과 KNN(K-Nearest Neighbors)이 각각 어떤 상황에서 더 효과 적인지 알아 보아라!
아래 조건을 고려하면서 공부해보자!
- 데이터 클러스터링(Data Clustering): 데이터가 어떻게 분포되고 클러스터(덩어리)를 이루고 있는지
- 클래스 불균형(Class Imbalance): 훈련 데이터에서 한 클래스가 다른 클래스보다 훨씬 많은 경우.
- 혼합된분류(Mixed Classification): 데이터가 많이 섞여 있는 상황(예: 빨간 점과 파란 점이 서로 뒤섰인 경우).
- 모델 신뢰도(Model Confidence): 새로운 데이터 포인트의 분류 결과가 얼마나 신뢰할 수 있는지.
먼저 다시 공부할겸 기본 개념을 간단히 하고 넘어가자!
SVM
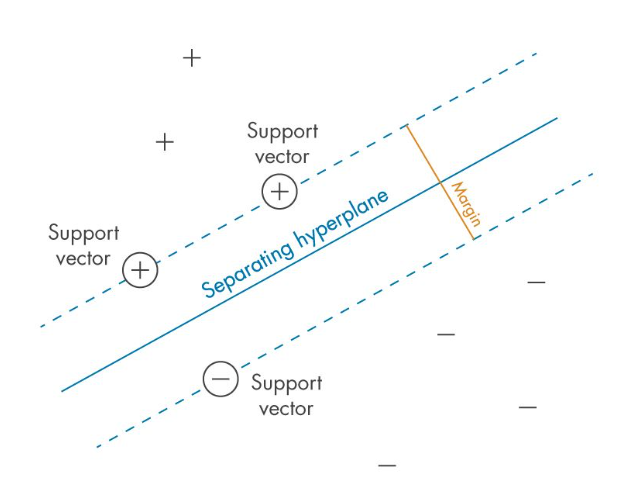
- 개념: SVM은 클래스 간의 경계를 최대 폭의 마진을 가진 초평면(hyperplane)으로 구분한다.
- 장점:
- 고차원 데이터에서 성능이 우수 하다.
- 클래스 간 경계가 명확할 때 효과적이다.
- 커널 트릭을 사용해 비선형 데이터를 처리 가능하다.
- 데이터 포인트와 초평면 간의 거리를 미용한 신뢰도 점수를 제공한다.
- 단점:
- 큰 데이터셋에서 계산 비용이 높다.
- 클래스 간 데이터가 많아 겹치면 성능이 떨어질 수 있다.
KNN 개념
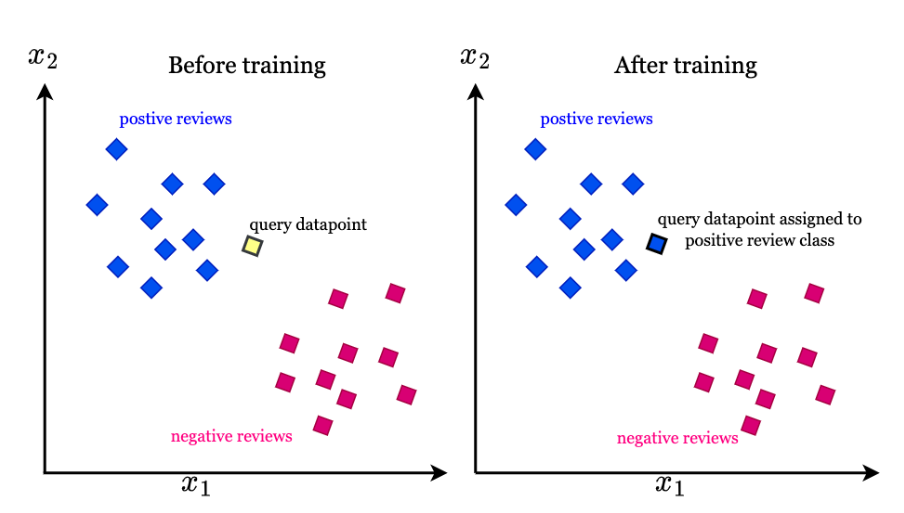
- 개념: KNN은 게으른 학습 알고리즘(lazy learning algorithm)으로, 새로운 데이터 포인트의 클래스는 가장 가까운 k개의 이웃의 다수결로 결정된다.
- 장점:
- 간단하고 직관적이다.
- 지역적 패턴과 비선형 경계를 잘 처리 한다.
- 학습 단계가 없고, 데이터 저장만으로 바로 사용 가능하다.
- 단점:
- 데이터셋이 클수록 거리 계산에 시간이 오래 걸린다.
- 노이즈나 불필요한 특징에 민감하다.
- 신뢰도 점수를 직접적으로 제공하지 않는다.(다수결만 사용)
SVM이 더 나은 경우
- 명확한 경계가 있을 때(Clear Class Boundaries): 데이터간의 경계가 뚜렷하고, 클래스가 잘 분리되는 경우.
- 고차원 데이터(High Dimensional Data): 텍스트 분류나 유전자 데이터 분석 등.
- 클래스 불균형(Class Imbalance): SVM은 마진을 조정해 클래스 불균형을 처리 가능하다.
- 혼합된 데이터(Mixed Data): 커널 트릭으로 복잡한 경계를 처리할 수 있다.
KNN이 더 나은 경우
- 비선형 경계(Non-linear): 데이터 경계가 복잡하거나 곡선 형태일 때.
- 작고 밀집된 데이터(Small, Well-Clustered Data): 소규모 데이터셋에서 각 클래스가 가까이 모여 있는 경우.
- 간단한 구현이 필요할 때(Low Training Effort): 학습이 필요 없으므로 빠르게 적용 가능.
예측 신뢰도와 관련된 차이점
- SVM: 초평면에서의 거리를 바탕으로 신뢰도를 제공한다.
- KNN: 이웃의 비율로 신뢰도를 유츄할 수 있으나, 명확한 점수는 제공하지 않는다.
정리
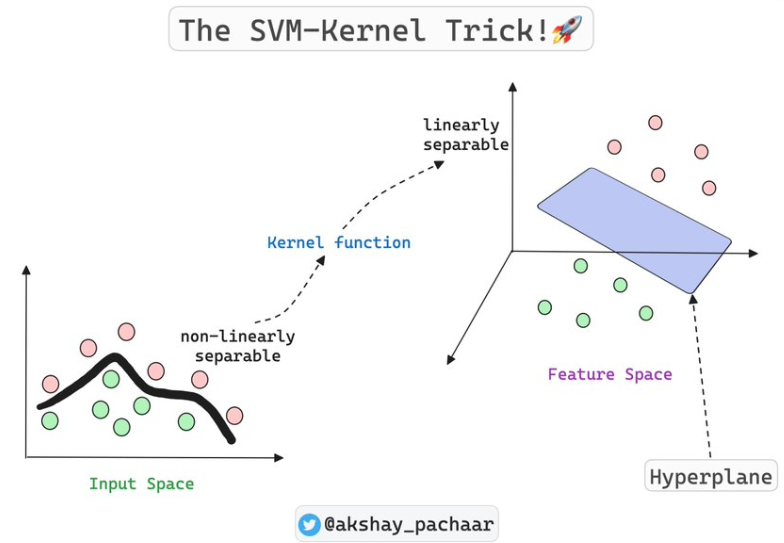
- SVM은 데이터 경계가 명확하거나 고차원 데이터에서 좋고 신뢰도 점수를 제공하는 장점이 있다.
- KNN은 비선형 경계나 지역적 패턴을 처리하는 데 적합하고, 간단한 구현이 필요할 때 유리하다.
- 데이터가 섞여 있으면 SVM은 커널 기법으로 복잡한 경계를 처리할 수 있고, KNN은 k값 선택에 신중해야 한다.
오 이제 조금 개념에 익숙해졌다! 아직 R은 어색하지만...
참고문헌:
https://se.mathworks.com/discovery/support-vector-machine.html
Support Vector Machine (SVM)
A support vector machine is a supervised learning method used widely for classification and regression tasks. Get started with code examples and tutorials.
se.mathworks.com
K Nearest Neighbours — Introduction to Machine Learning Algorithms
Used to solve classification type problems
medium.com
https://intuitivetutorial.com/2023/04/07/k-nearest-neighbors-algorithm/
K-Nearest Neighbors Algorithm - Intuitive Tutorials
An article explaining basic principles of K-nearest neighbors algorithm, working principle, distance measures, and applications are discussed.
intuitivetutorial.com
** 그냥 하루하루 개인 공부한 것을 끄적 거리는 공간입니다.
이곳 저곳에서 구글링한 것과 강의 들은 내용이 정리가 되었습니다.
그림들은 그림밑에 출처표시를 해놓았습니다.
문제가 될시 말씀해주시면 해당 부분은 삭제 하도록하겠습니다. **
'public void static main > AI' 카테고리의 다른 글
| [DataModeling] 데이터 검증, 분할 (0) | 2025.01.15 |
|---|---|
| [Discussion] KNN(K-Nearest Neighbors)알고리즘에서 스케일링(Scaling)이 중요한 이유 (1) | 2025.01.14 |
| [DataModeling] 회귀분석(Regression Analysis) (2) | 2025.01.14 |
| [Discussion] Scaling이 적합한 상황과 Standardization이 적합한 상황 (2) | 2025.01.13 |
| [Discussion] SVM은 왜 larger margin을 선호할까? (0) | 2025.01.12 |




댓글