반응형
하... 이제 수업 시작이구나........ 너모너모 공부할께 많다........
이 시간만 잘 버텨내면 어제보다 조금 더 아는 사람이 될꺼야!
이글은 시험준비를 위한 나만의 학습 내용이다!

분류(Classification)
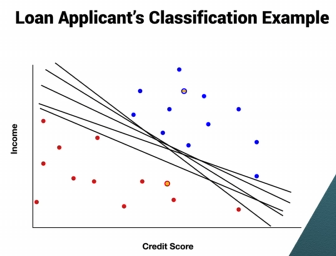
- 데이터를 "예/아니오" 또는 다중 카테고리로 나누는 작업을 의미한다.
- 예시: 대출 승인, 이메일 필터링, 질병 탐지 등.
- 소득, 신용 점수와 같은 데이터 속성을 이용하여 새로운 데이터를 분류할 모델을 만든다.
- 그래프에서는 축에 속성을 배치하고, 선으로 카테고리를 구분한다. (파란색은 승인, 빨간색은 거절)
- Classifier 로 학습을 시켜준 다음(이색은 red, green, blue다) 학습된 클래스로만 대답을 하는 것을 Classification이다.
- Regresstion(회귀): 사람의 몸무게를 줬을때 이사람의 키를 예측하라! (회귀는 다음시간에 공부해보자...)

분류에 대한 수학적 모델
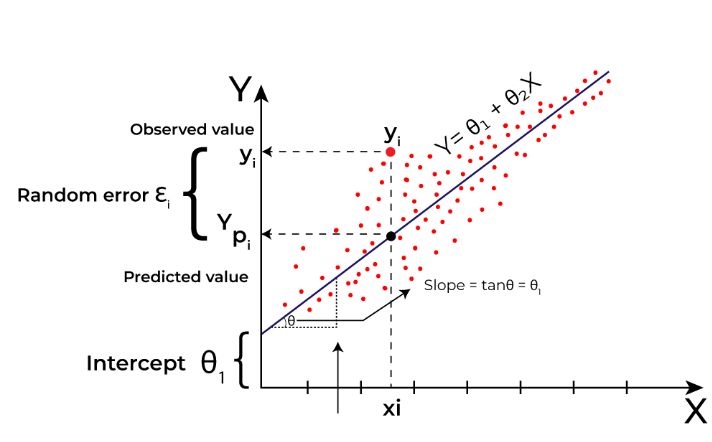
- 목표: 데이터 카테고리 간 거리를 최대화 하는 선을 찾는 것.
- 완벽한 분리는 어렵다.
- 오류를 정량화 하고, 오류 최소화와 여유폭 최대화 간의 균형을 조정하는 것이 목표!
분류 선(Classification lines)
- 불완전하거나 불확실한 데이터로 인해 오류를 최소화 해야한다.
- 완벽한 분리가 불가능 할 때는 "soft classifier(소프트 분류기?)"를 사용하여 오류와 근접 오류의 균형을 맞춰야한다.
- 오류 비용에 따라 경계를 조정하는 비용 민감 분류를 다룬다.
- 속성의 중요성: 때로는 적은 속성으로도 분류가 가능하다.
데이터(Data)
- 데이터는 일반적으로 행(데이터 포인트)과 열(속성/특징)으로 구성된 표로 간주된다.
- 데이터 유형: 구조화된 데이터(예: 숫자, 범주형 값)와 비구조화된 데이터(예:텍스트).
- 이진 데이터는 두 가지 값(예: 예/아니오)을 가진 범주형 데이터의 하위 유형이다.
- 시계열 데이터는 시간에 따라 관련된 관측치로, 간격이 일정하거나 불규칙할 수 있다.
서포트 백터(Support Vectors)
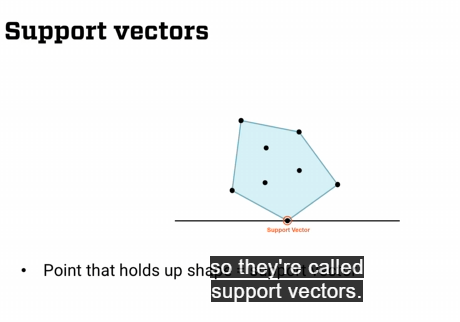

- 서포트 백터는 분류기(classifier)의 경계(여유폭)을 정의하는 중요한 데이터 포인트 이다.
- The classifier는 서포트 백터가 결정하는 두 평생선 사이에 위치 한다.
- 서포트 백터는 classifier의 일부는 아니지만, 이를 정의하는 데 중요한 역할을 한다.
오류 비용(Error Costs)
- 일부 분류 오류는 다른 오류보다 비용이 더 높다.
- 예를 들어, 잘못된 대출 승인 비용은 올바른 대출 거절보다 더 높다.
- SVM은 오류 유형별로 다른 패널티를 부여할 수 있다.
데이터 준비(Data Preparation)
- 데이터 스케일링(Data scaling)은 서로 다른 범위를 가진 속성(예: 신용 점수와 소득)이 동일하게 처리되도록 보장한다.
- 계수가 0에 가까운 속성은 관련성이 낮아 제거할 수 있다.
비선형 분류기(Non-Linear Classifiers)

- SVM은 커널 방법을 사용하여 비선형 분류를 처리할 수 있다.
- 이런 커널은 데이터를 고차원으로 변환하여 더 복잡한 결정 경계를 허용한다.
확률기반 모델과 비교(Comparison with Probability-Based Models)
- SVM과 달리 로지스틱 회귀는 분류를 위한 확률을 추정한다.
- 확률 모델은 결정 신뢰 수준이 중요한 경우에 더 적합할 수 있다.
SVM(Support Vector Machine)이 뭔데!?
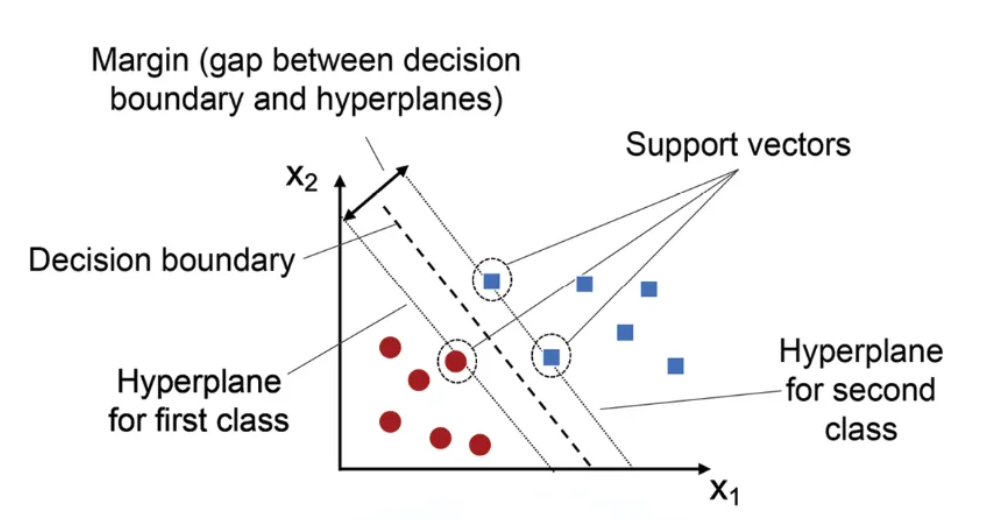
- SVM은 데이터의 두 클래스를 가장 잘 구분하는 선(또는 마진)을 찾는 분류 기법이다.
- 머신러닝의 분류(Classification)와 회귀(Regression) 문제를 해결하는데 사용되는 강력한 알고리즘이다!
- 완벽한 분리가 불가능한 경우, 분류 오류를 줄이는 것과 마진을 최대화 하는 것 사이에서 균형을 맞춘다.
SVM 주요 개념
- 기본 아이디어: 데이터를 선(또는 초평면)으로 나누는 것
- 데이터를 두 개 이상의 카테고리로 나누는 선(2D) 또는 초평면(고차원)을 찾는 알고리즘이다.
- 예:
- 대출 승인 여부(승인 vs 거절).
- 스팸 이메일 분류(스팸 vs 정상).
- 예:
- 데이터를 두 개 이상의 카테고리로 나누는 선(2D) 또는 초평면(고차원)을 찾는 알고리즘이다.
- 최적의 경계선 찾기
- SVM은 여러 경계선 중에서 가장 안전한 선(마진을 최대화 하는 선)을 찾는다.
- 마진:
- 선과 데이터 점 사이의 거리
- 이 거리를 최대화 하면 새로운 데이터가 들어와도 정확히 분류될 가능성이 높아진다.
- Support Vector
- 경계선 가까이에 있는 데이터 포인트를 Support Vector라고 한다.
- 이 포인트들이 경계선을 정의하는 데 중요한 역할을 한다.
SVM이 작동하는 방식
- 선형 분류
- 데이터가 선으로 나눌 수 있는 경우.
- 비선형 분류
- 데이터가 복잡하게 얽혀 있을 때, SVM은 커널 트릭(Kernel Trick)을 사용해 데이터를 고차원으로 변환한 뒤 선형으로 나눈다.
- 커널: 데이터를 다른 차원으로 매핑하는 함수
- 데이터가 복잡하게 얽혀 있을 때, SVM은 커널 트릭(Kernel Trick)을 사용해 데이터를 고차원으로 변환한 뒤 선형으로 나눈다.
- 오류 허용(Soft Margin)
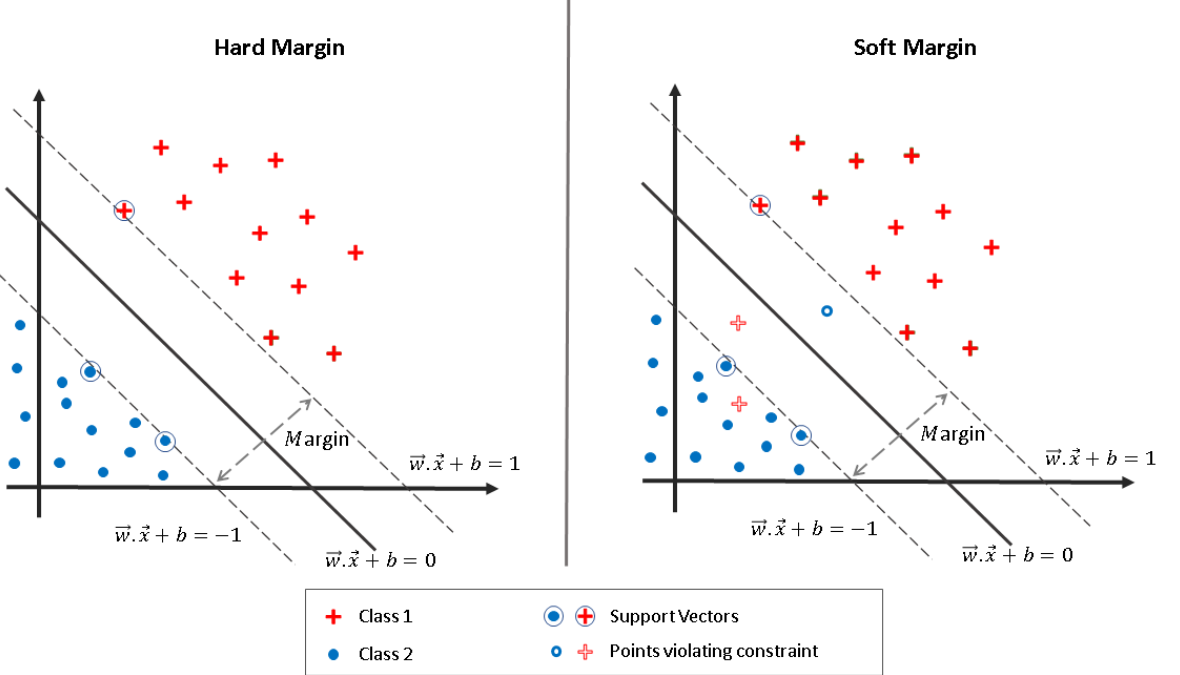
- 완벽히 분리되지 않는 데이터에서 SVM은 약간의 오류를 허용해 최적의 경계선을 찾는다.
ㅇ으ㅏ아아ㅏㅏ아ㅏㅏㅏㅏㅏㅏㅏ아ㅏㅏㅏㅏㅏ
** 그냥 하루하루 개인 공부한 것을 끄적 거리는 공간입니다.
이곳 저곳에서 구글링한 것과 강의 들은 내용이 정리가 되었습니다.
그림들은 그림밑에 출처표시를 해놓았습니다.
문제가 될시 말씀해주시면 해당 부분은 삭제 하도록하겠습니다. **
반응형
'public void static main > AI' 카테고리의 다른 글
| [Discussion] KNN(K-Nearest Neighbors)알고리즘에서 스케일링(Scaling)이 중요한 이유 (1) | 2025.01.14 |
|---|---|
| [Discussion] SVM(Support Verctor Machine)과 KNN(K-Nearest Neighbors) (1) | 2025.01.14 |
| [DataModeling] 회귀분석(Regression Analysis) (2) | 2025.01.14 |
| [Discussion] Scaling이 적합한 상황과 Standardization이 적합한 상황 (2) | 2025.01.13 |
| [Discussion] SVM은 왜 larger margin을 선호할까? (0) | 2025.01.12 |




댓글